资源链接
- 代码:https://github.com/NathanUA/U-2-Net
- 论文:https://arxiv.org/pdf/2005.09007.pdf
- 评价指标:https://github.com/NathanUA/Binary-Segmentation-Evaluation-Tool
论文题目
U Square Net: Going Deeper with Nested U-Structure for Salient Object Detection
摘要
设计优点
- RSU block使得stage内可以捕获到更多scale的contextual的信息;
- RSU不会在计算量上增加过多主要得益于RSU内部的pooling操作;
模型特点
U^{n} Net, where n = 2;
可以train from scratch,且效果和那些用预训练的模型效果差不多甚至更好;
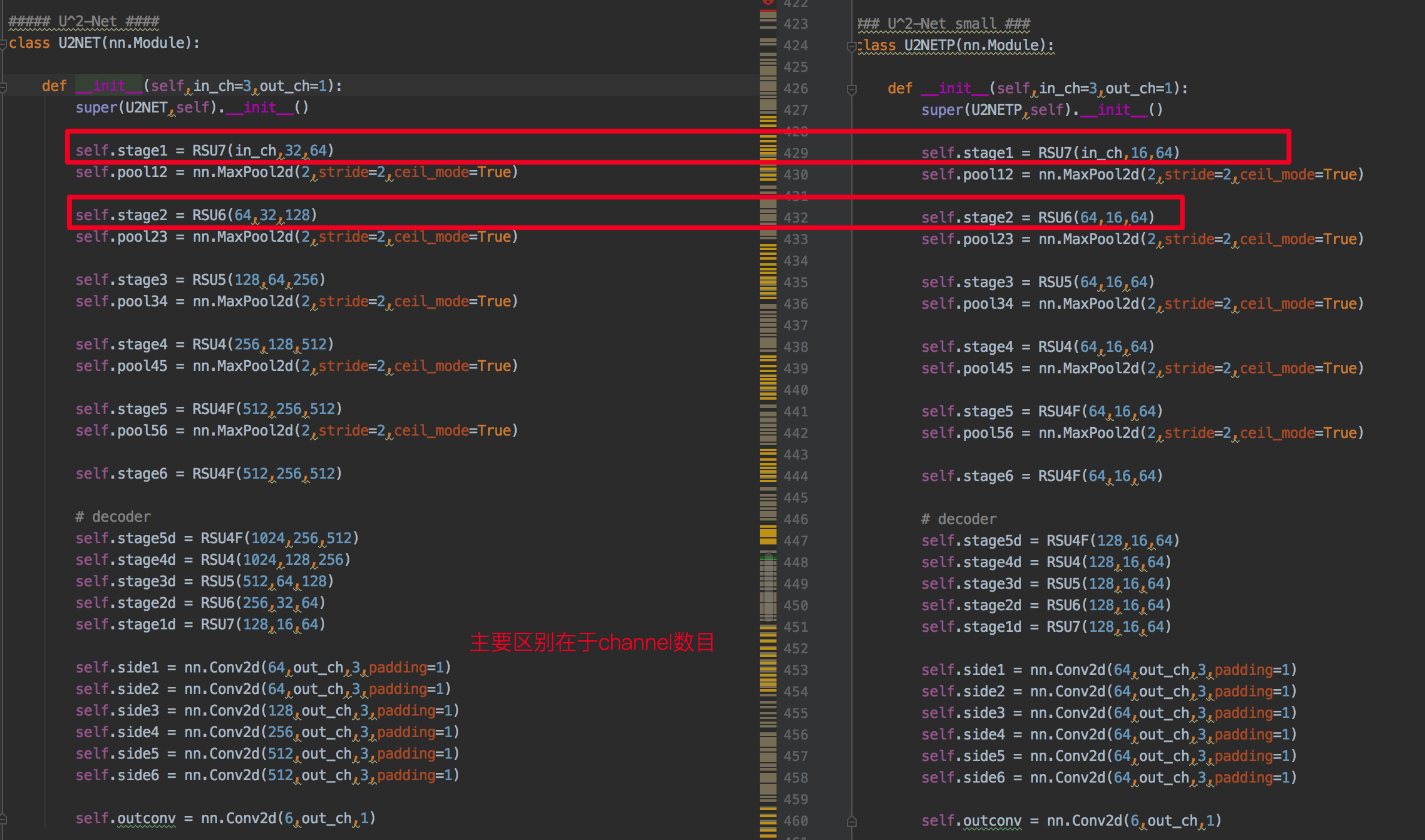
提供了一个重版但效果最好和轻量版效果稍微差一点点的模型,模型框架基本一致,主要在于通道参数不同。

介绍
- 作者认为之前SOD的设计一直都存在一种common pattern,即借助于一些用于分类任务的预训练模型作为backbone进行SOD模型finetune的基础,但这其中存在的问题是,分类任务更关注的是全局语义信息而损失了SOD任务额外需要的局部细节信息和全局对比信息;此外,实际训练过程中的目标数据可能和ImageNet这种大型公开数据库的分布相差很大。由此,作者发问,是否可以设计出来一种模型结构,可以非常简单地train from scratch,同时可以媲美现有sota甚至超过它们。
- 作者还觉得现在的SOD模型设计越来越复杂,而且为了加深网络模型不惜让feature map越来越步入到 low-res 的境地,而 high-res在SOD中是非常重要的。因此,作者再次发文,是否存在一种方法可以在 go deeper的同时,不过多损失resolution且计算量是可接受的。
对于问题1,作者设计了nested U-Net这种结构,可以train from scratch;对于问题2,作者设计了RSU block,保证了intra-stage的特征图resolution的不变性,同时intra-stage内可以捕获多scale的特征。
RSU Block
先上一张对比图,

作者认为图中a-c的卷积核主要以3*3为主,难以捕捉到全局信息,而d的话虽然想要通过引入dilated conv,但是计算量和显存都会增大;虽然PoolNet想要通过池化的方法降低计算量,但是作者认为将特征图直接upsample之后相加对high-res的特征是无益的。

一个RSU block主要由三部分组成,如图所示,1为输入卷积层,2是一个U-Net like的操作,3是一个残差链接。更形象地表达方式如下图中的右图所示,

U Square Net
nested instead of stack.

从上图可以看出,模型结构主要由三部分组成,encoder(最左边)+decoder(中间,多监督)+fusion module(最右边)。
需要注意的点,En_5和En_6的输入特征图res太低,如果进一步downsample的话,会损失context信息,因此作者这时候选择的是dilated conv。同理De_5。
损失函数

其中每一个loss都是交叉熵损失函数。